Table of Contents
- Objective
- What We Previously Knew about Transformers
- Context Free Grammar
- Transfomers Learning CFGs
- How Transformers Learn CFGs
- Conclusion
Objective
We want to design numerous, controlled experiments AND probe into the network, to statistically uncover the mechanisms behind how diverse Al tasks are being accomplished via pretraining / finetuning. This is more like experimental physics than neuroscience.
What We Previously Knew about Transformers
Induction Heads
- Seeing ...[A][B]..., some transformer heads are in charge of making the induction: [A] -> [B]
- "In-context Learning and Induction Heads" from Anthropic in 2022
- Can fulfull tasks such as sequence copying, translation, and pattern matching
- More complex induction heads may come from deeper layers of the transformer
Inhibition Heads & Name Mover Heads
- "Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small"
- When Mary and John went to the store, John gave a drink to ___. The inhibition head is in charge of not using John again if John already appeared in the sentence.
- Name Mover Head: moving a name to later of a sentence
- Backup Name Mover Head: if the Name Mover Head fails, the Backup Name Mover Head will move the name to the end of the sentence
- The author mentioned: "to the best of our knowledge, ...the most detailed attempt at reverse-engineering a natural end-to-end behavior in a transformer-based language model."
Conclusion
It's very hard to reverse-engineer the behavior of a transformer-based language model.
Context Free Grammar
Demo
Non-Terminal symbols -> Terminal Symbols
root -> a b c
root -> a d
a -> b E
a -> F c
b -> d d
b -> d G
C -> G G
d -> G F
d -> F G
Example:
root -> a b c
-> b E d d G G
-> d G E G F F G G G
-> G F G E G F F G G G
Property #1: Long-range Planning
- Example: "...Y(...)[[...]]X".
- X depends on Y that could be hundreds of tokens before
- Note: this is not captured by "induction head"
Property #2: Locally Ambiguous
- GG can come from many different NTs
- Example: "c -> GG", "bd -> dGGF", "bcd -> dGGGGF"
- Bracket matching is not so locally ambiguous: e.g. ([])
- English grammar is not so locally ambiguous: e.g. ADJP
<=>RB JJ | JJ PP
Transfomers Learning CFGs
Synthetic CFGs
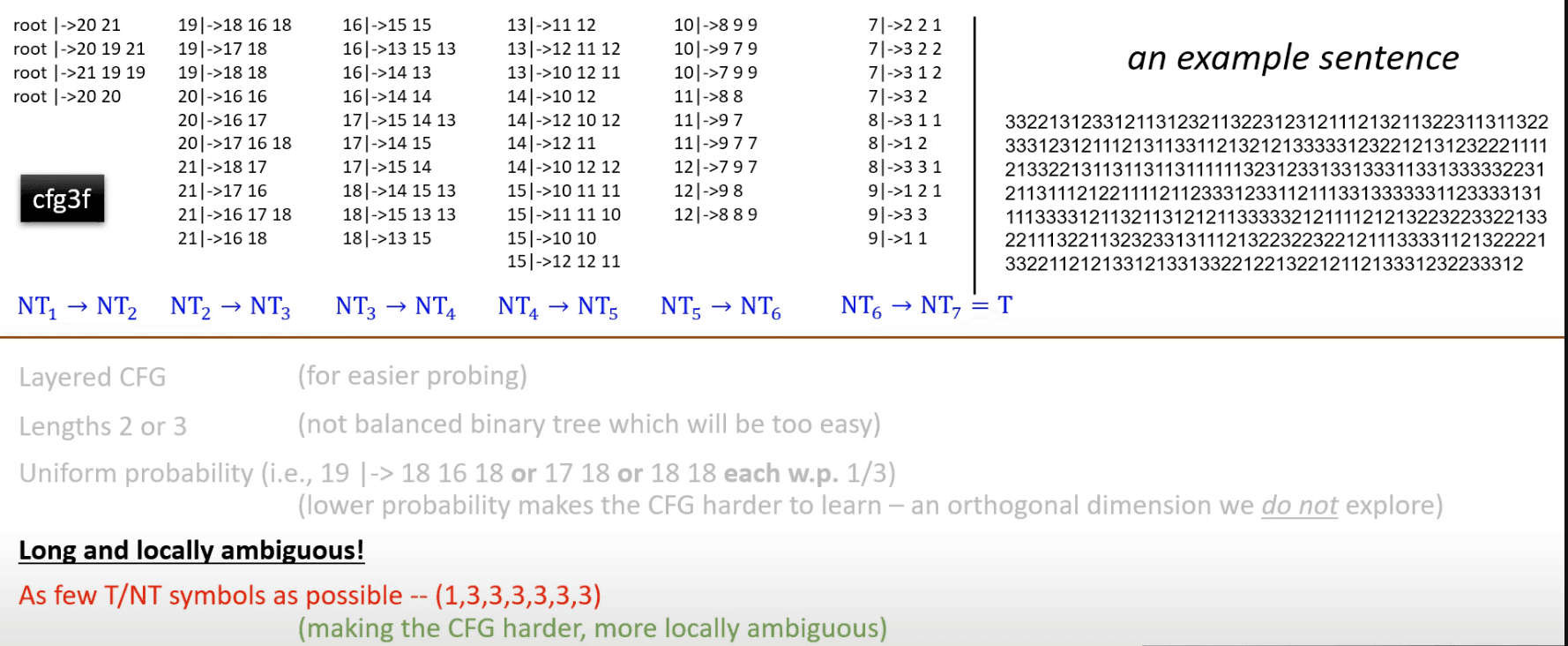
- The global parsing tree is still unique - you can use dynamic programming to parse the globally unique solution
- We ask the transformer to learn the CFGs without the CFGs being given, which is harder than the most naive version of dynamic programming
- About 10^80 strings satisfy cfg3f among 10^140 possible strings of length 300 or more
Can We Use GPT2-Small to Learn CFGs?
- 12 layer, 12 head, 768=12*64 dimensions
- GPT2 pretrained on cfg3f data (infinite amount, online data)
- Generation accruacy: let the model generate from "start" token (using temperature 1)
- Completion accuracy: generate a competion from x:50 (using temperature 1)
Results 1.0
- GPT with relative and rotary embedding works much better than (99 vs 64) GPT with absolute embedding
- First takeaway: we should abandon absolute embedding
- GPT with position-based attention (Att_i->j only depends on i,j) and GPT with uniform attention (hth head looks back at 2^h-1 tokens with uniform weights) did not perform as well as the state-of-the-art GPT (99 vs 94).
Results 1.2 - Generation Diversity
- GPT might memorize the same sentence and repeat it
- Entropy estimation: sum of the log of the conditional probabilities of the sentences. All models are on the same level.
- Output generated by GPTs is as diverse as the ground truth
Results 1.3 - Generation Distribution
- Are we generating it using the correct probability comparing to the ground truth?
- Vanilla GPT is bad. GPT with relative attention and GPT with rotary embedding performed better.
How Transformers Learn CFGs
Evidence that Transformer Learns to do Dynamic Programming
- Result 2: hidden states encode NT ancestor/boundary info.
- Result 3: attention favors "adjacent" NT-end pairs i, j
- DP = storage + recurrent formula
- DP (i, j, a) = whether xi, xi+1,...x; can be generated from symbol a following the CFG rules.
- Thus, learning NT-ancestors/boundaries -> learning a "backbone" of necessary DP(i, j, a) on the correct CFG parsing
- ... we (intentionally) did not prob those DP(i, j, a) not in the "backbone"
- ... even when human writes this DP, depending on the pruning, the order of the loops...
Robustly Pretrained GPT
- Pretraining
- Vanilla pretrained GPT trained on the correct CFG data
- Robustly pretrained GPT trained on the perturbed CFG data (with some fraction of data perturbed)
- Results
- Vanilla pretrained GPT is not very robust against correpted prefixes while robustly pretrained GPT is robust against corrupted prefix
- Robustly pretrained GPT learns to mode-switch between the correct and incorrect data at temperature 1.0
Conclusion
🌟 Transformer learns a "backbone" of necessary DP(i, j, a) shared by all DP implementations
🌟 We should abandon aboslute positonal embedding
🌟 Masked-Language Modeling (BERT) is incapable of learning something deep in the language while Language Modeling (GPT) is capable of doing that
🌟 It's important to also include corrupt data (e.g. sentences with grammar mistakes) in the pretaining. During test, a low temperature needs to be chosen. Otherwise, the model will switch between correct data and incorrect data
References:
- https://arxiv.org/abs/2305.13673
- https://www.youtube.com/watch?v=kf_eGgVtOcs